java中为我们提供了很多实用的数据结构,常用的大体上分为两大类:根类为
AbstractCollection的单集合容器,以及根类为AbstractMap<K,V>的双集合容器。我们一般本着从最顶层(顶层包含该数据结构的所有公共方法和字段)开始学习,从最底层(顶层包含数据结构的具体实现和特有方法)开始使用的原则,来总结以上两大数据容器。
AbstractCollection – 单集合容器

如上图所示:AbstractCollection这个抽象类实际上实现了对应接口Collection,在Collection中定义了所有单集合容器都应具有的特性。
首先我们一起看一下Collection接口的JDK注释
1 | * The root interface in the <i>collection hierarchy</i>. A collection |
从中,我们可以总结出Collection的几大特点:
- 子类中既存在允许重复值(如
LinkedList、ArrayList),也存在不允许重复值(如HashSet) - 子类中既存在有序的(如
LinkedList、ArrayList),也存在无序的(如HashSet) - 子类中既存在不包含index的(如
HashSet),也存在包含index的(如LinkedList、ArrayList)
对应Collection的一些共有的抽象方法,如下图所示:
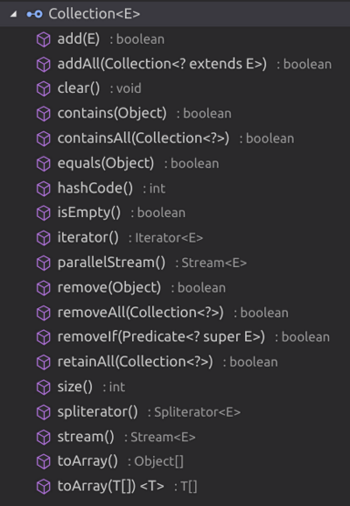
其中Collection的增、删,分别对应着add(E element)、remove(Object)、clear()(清空集合)
另外,集合的遍历涉及到的两个函数toArray()以及iterator(),我们需重点掌握。
使用toArray()遍历集合
1 | //利用了向上多态转型 |
使用迭代器Iterator遍历集合
1 | //利用了向上多态转型 |
注意:使用迭代器时不要对原集合进行操作,否则会出现并发修改异常
Collection子类精讲
说完了Collection父类的的共有特性和通用操作,现在聊聊其具体子类的一些独有特点。通过继承关系图,我们可以知道Collection可以分为四类:Queue、Deque、List和Set。下面我们主要谈谈List和Set:
List接口
先来一段JDK说明
1 | * An ordered collection (also known as a <i>sequence</i>). The user of this |
其特点可以用如下关键词形容:有序、存在索引、允许重复
常用方法有add(int index, E element)、remove(int index)、set(int index, E element)、get(int index),这些是不同于Collection,List所特有的方法。
LinkList和ArrayList之大比拼
在父接口List下,我们接触最多的就是LinkList和ArrayList了。下表是对它们的总结:
| 类名 | 特点 | 特有方法 |
|---|---|---|
| ArrayList | 底层用可变数组对List进行了实现 按index查找很快–O(1) 但按值进行查找速度很慢–O(n) 修改元素–O(1) 删除涉及到数组的移位,也很慢–O(n) 尾部添加元素,需要扩大数组–O(n) 指定位置添加,需要移动其他元素–O(n) | 没有,方法基本和List一样 |
| LinkedList | 底层用双向链表实现 按index查找不能像数组那样,还是得一个节点一个节点遍历–O(n) 按值查找同上–O(n) 修改元素和删除很快–O(1) 尾部添加元素–O(1) 指定位置添加元素–O(1) | addFirst(E e) addLast(E e) getFirst( ) getLast( ) removeFirst( ) removeLast( ) |
使用指南:
- 如果业务查询多,添加和删除少,优先考虑
ArrayList - 如果业务添加和删除多,查询少,优先考虑
LinkedList - 一般情况,使用ArrayList就可以了
set接口
首先看一下其JDK注释:
1 | * A collection that contains no duplicate elements. More formally, sets |
set的概念和数学上集合的概念基本一致,即:无序、无重复、无索引
其常用方法和Collection一样:add(E element)、remove(Object)和clear()
HashSet – 存储自定义对象
先看一下JDK中对其的定义:
1 | * This class implements the <tt>Set</tt> interface, backed by a hash table |
从以上注释可知,HaseSet的底层是由HashMap实现的。这里我们可以看一下其源码实现:
1 | * Adds the specified element to this set if it is not already present. |
AbstractMap – 双集合容器

如图,AbstractMap是相对于AbstractCollection而言,又一抽象数据结构的顶层父类。不同于AbstractCollection单集合特点,在AbstractMap结构中存在着两个集合,且维护着这两个集合之间的对应关系。
先看一段JDK注释:
1 | * An object that maps keys to values. A map cannot contain duplicate keys; |
从中,我们可以总结Map的几大特点:keys –>value映射、key是set、value是Collection
Map中常用方法有:
| 方法 | 作用 |
|---|---|
| void clear() | 清空map |
| Set<Map.Entry<K, V>> entrySet() | 返回map中键值对集合 |
| boolean equals(Object o) | 比较两个map是否相等 |
| int hashCode() | 计算map的hash值 |
| V get(Object key) | 根据key获取map中value |
| V put(K key, V value) | map中添加key-value对 |
| V remove(Object key) | 根据key移除键值对 |
| Set | 获取map所有的key |
| Collection | 获取map所有的value |
| Set<Entry<K,V>> entrySet() | 获取键值对集合 |
Map内部接口Entry<K,V>中常用方法:
| 方法 | 作用 |
|---|---|
| K getKey() | 获取键值对中的key |
| V getValue() | 获取键值对中value |
| V setValue(V value) | 设置键值对中的value |
| boolean equals(Object o) | 比较两个键值对是否相等 |
| int hashCode() | 返回键值对的hash值 |
同上,map的遍历我们也有两种方法:
使用keySet()和get(Object key)进行map遍历
整个过程可以简单理解成:先获取“key集合”,再通过key找value,获取全部键值对,代码如下:
1 | Set<K> keys = map.keySet(); |
使用entrySet()进行遍历
整个过程可以理解为:先获取”键值对集合“,再通过键值对,获取key和value
1 | Set<Map.Entry<K,V>> entries = map.enrtySet(); |
Map子类精讲
这里我们主要总结HashMap的常用操作,详情请参考java – HashMap详解