偶然看到了一道有关java基本数据类型中变量相加和常量相加的面试题,觉得很有意思,先总结如下
题目
1 | byte b1=1, b2=2, b3, b4; |
题目咋一看,似乎很简单。两个数相加,不就是考虑数据类型是否一致,以及运算结果是否会溢出的问题吗?
照着这一思路,我首先判断第2行的代码应该是没有问题的,理由如下:(1)变量b1和b2都是byte类型变量;(2)b1+b2结果为3,没有超出byte的存储空间-128~127。
至于第3行代码,是两个常量相加,再将结果赋值给变量b4,应该也不存在编译问题。
编译
编译输出结果如下:
1 | Error(3):java: incompatible types: possible lossy conversion from int to byte |
第3行编译报错,第4行通过编译
分析
初步断定是数据类型转换失败,因为int向byte转换时,会存在精度丢失的问题。
那么,这里的int数据又是哪里来的呢?难道byte类型的b1和b2相加,结果被自动转成了int?
带着这些疑问,我查阅了相关资料,发现原来在java中基本数据类型在进行运算时,普遍存在着所谓自动数据类型转化问题。之间的转化图可以总结如下:
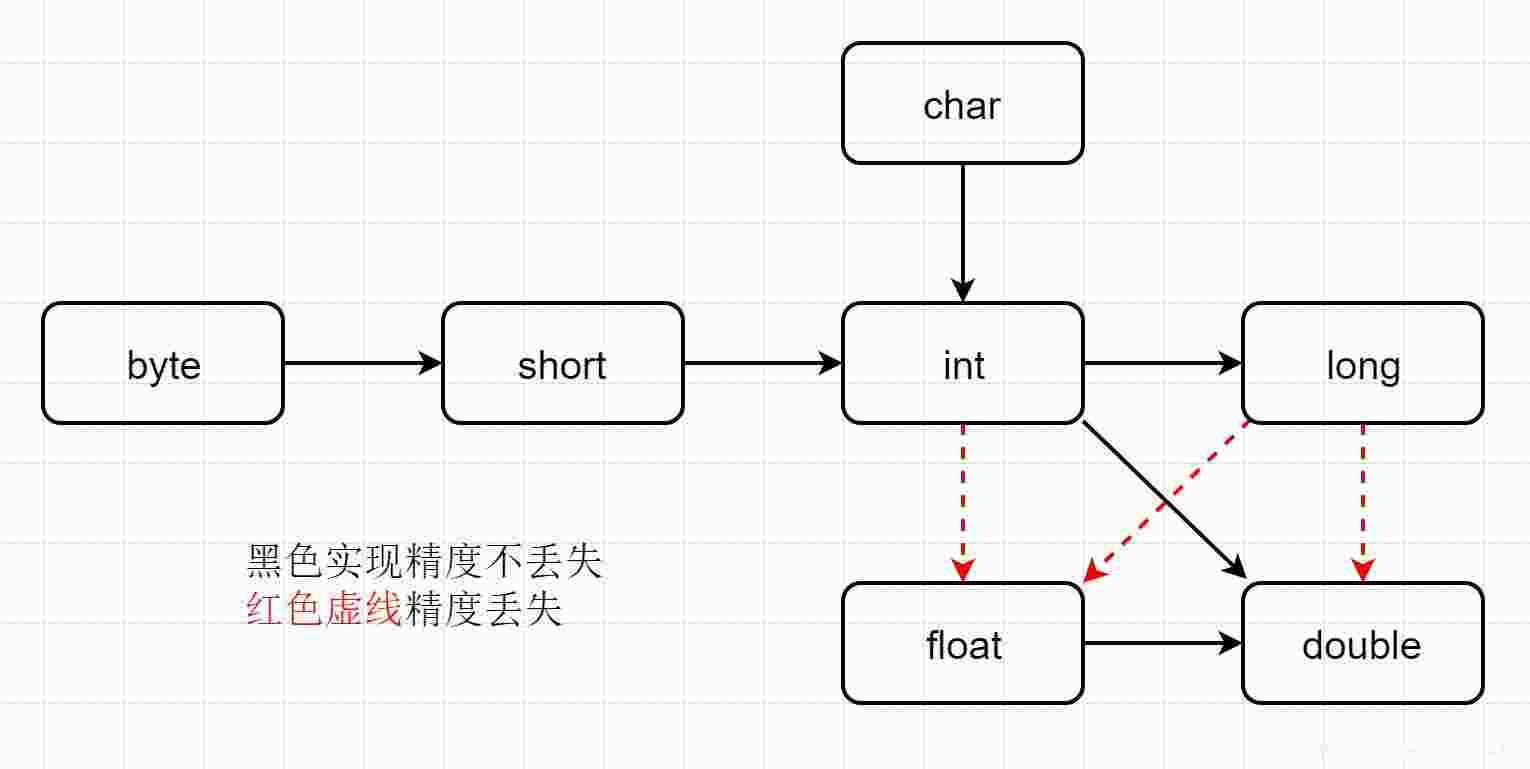
其中红线表示可以在不丢失精度的情况下完成转化,而蓝线则意味着转化后可能会损失部分精度;不管怎样,图中所有转化,都是java编译器所允许的自动类型转换。
相关规则是:
当byte、short、int、long、char等数据类型在一起运算,即只有整型数据参与运算时:无long型,所有非int类型转成int类型;有long类型,都转成long类型。
当float、double等数据类型一起运算,即只有浮点型数据参与运算时:一律转为double类型进行运算。
当所有数据类型混在一起运算,即整数和浮点数据类型同时存在时:一律转为double类型进行运算。
另外还需要注意的是:整型数据的默认类型为int,浮点型则为double。一般数据运算都先转为默认数据类型,然后才开始运算;除非有更高级别的数据类型存在,比如规则1中存在long型,则都转为long(虽然默认数据类型是int)
再回到那道面试题,两个byte类型的变量进行加法运算,编译器在编译这行代码时会自动将其类型转换为整型默认数据类型int,这种现象也叫做java的自动类型提升。
从反编译看数据类型转换
另外,借助反编译工具procyon.jar,我们可以从代码执行的底层进一步窥探到java数据类型转换的过程。由于b3 = b1 + b2;编译不通过,现将原始代码修改如下:
1 | byte b1=1, b2=2, b3, b4; |
反编译如下:
1 | b1 : byte |
从第8行,我们可以知道b1+b2,结果是以int类型保存的,故源码中我们企图将其运算结果赋值给b3会报数据类型不匹配的错误。
而1+2这个常量运算式,编译器是先将其结果计算出后,再根据其要被赋值的变量类型(这里被赋值的变量类型是byte),动态分配存储空间的。
总结
变量相加:一般是先开辟内存空间(根据参与运算的变量类型决定,规则见上面的分析),然后进行相关操作。
常量相加:一般是编译器先帮我们算出结果,然后根据所要赋值的变量类型开辟相应内存空间。